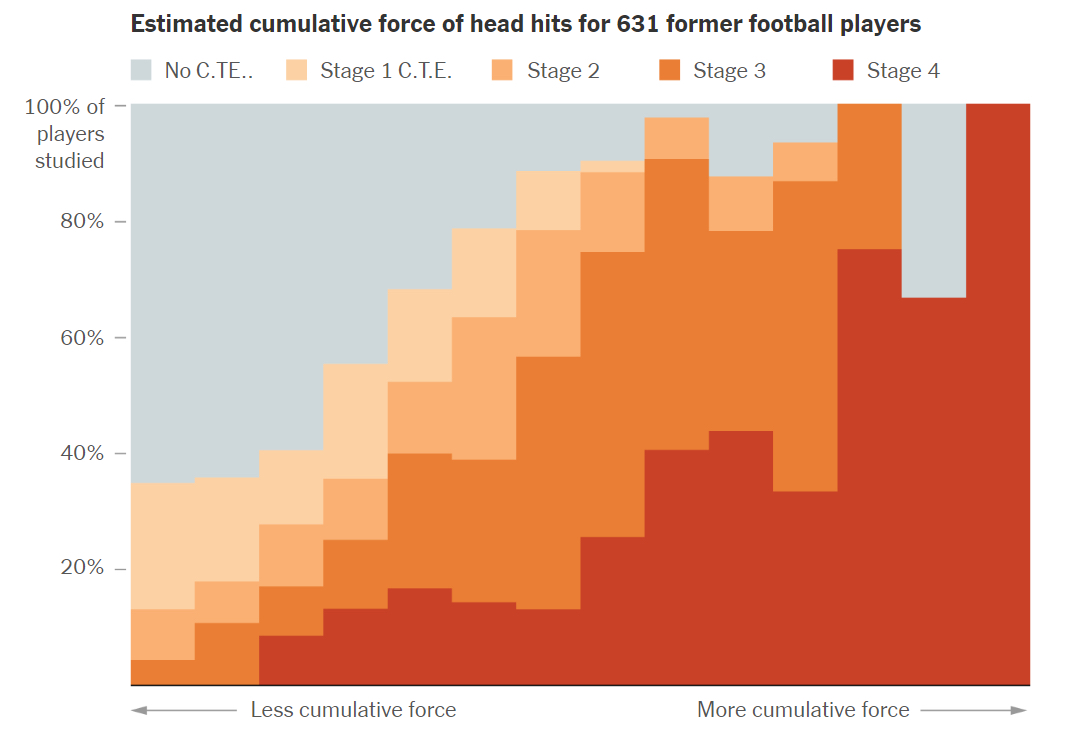
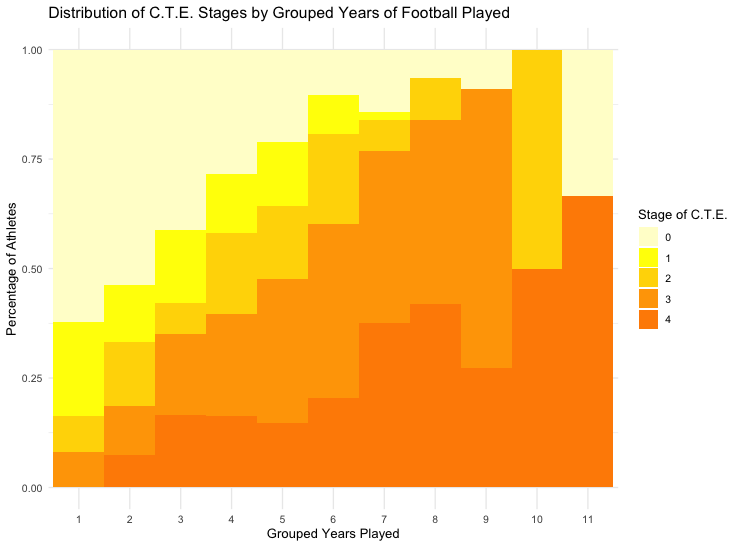
The original graph came from a New York Times project called “What’s Going on in this Graph?” This one was about football and the possible link to chronic traumatic encephalopathy (CTE).
The first prompts for ChatGPT 4 to create the original began with me attaching an image of the original and a copy of the data that was downloaded from the research article. The prompt was:
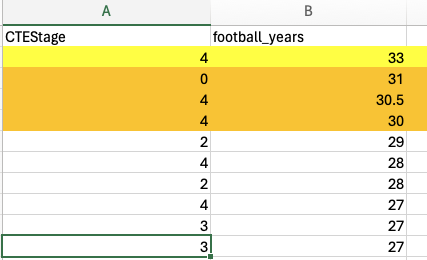
“I have the data to make this graph based on the spreadsheet I shared.”CTEStage” contains the stage cte stage and “football_years” is the cumulative force that is measured in years of football played (on the x axis). the x axis is percentage of athletes with given number of years played (football_years) can you now generate the R code to recreate the graph?”
This is the code for the first output:
library(ggplot2)library(readxl)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(tidyr)library(here)
here() starts at /Users/andrewruiz/andrew_ruiz-MADA-portfolio
# Set up the path to the Excel file using here()file_path <-here("presentation-exercise", "EX6_mod.xlsx")# Read the data from the Excel filedf <-read_excel(file_path)print(colnames(df))
[1] "CTEStage" "football_years"
# Assuming your df has 'CTEStage' and 'football_years' columns# Convert 'CTEStage' to a factor if it's not alreadydf$CTEStage <-factor(df$CTEStage, levels =c("No C.T.E.", "Stage 1", "Stage 2", "Stage 3", "Stage 4"))# Calculate the percentage of players for each football_yeardf_summary <- df %>%group_by(football_years, CTEStage) %>%summarise(count =n()) %>%mutate(percentage = count /sum(count)) %>%ungroup()
`summarise()` has grouped output by 'football_years'. You can override using
the `.groups` argument.
# Spread the data for plottingdf_wide <- df_summary %>%spread(key = CTEStage, value = percentage, fill =0) %>%arrange(football_years)# Compute the cumulative sum for stackingdf_long <- df_wide %>%gather(key ='CTEStage', value ='value', -football_years) %>%arrange(football_years, CTEStage) %>%group_by(football_years) %>%mutate(cumulative_value =cumsum(value))# Plottingggplot(df_long, aes(x = football_years, y = cumulative_value, fill = CTEStage)) +geom_area(alpha =0.6, position ='stack') +scale_x_continuous(labels = scales::percent_format(scale =1)) +scale_fill_brewer(palette ="OrRd") +theme_minimal() +labs(x ="Percentage of Athletes with Given Number of Years Played (football_years)",y ="Proportion of Players",fill ="Stage of C.T.E.",title ="Estimated cumulative force of head hits for former football players")
Refining the prompts
The next series of prompts provided more specifics:
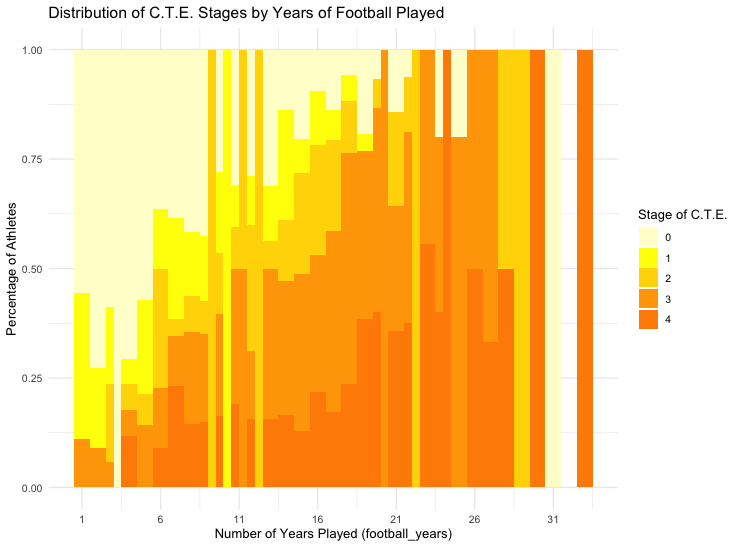
the x axis should be the number of years played (football_years) from 1 to 33. the y axis is the the percent of athletes for each number of years played. it should be a stacked bar graph by football_years. the bars should all have the same order. the bottom should be stage 4 the top should be 0. also 4 should be dark orange 3 lighter orange, 2 dark yellow, 1 yellow, 0 cream. the bars should be wide enough to touch each other and I want the x axis label just to show every 5 years.
The result was better, but still not the same as the NYT article. However, it was very similar to the orginal graph published in the research paper.
Attempt 2
##Re-examining the NYT graphic #### Upon closer inspection, the NYT graph grouped the number of years of football played into 14 categories. Their process for doing this was not shared in the article. However, it was apparent that they included the final last reported year (33) of the number of years plays in it own category. This is odd because there is only one observation for 33 years of football. I suspect that grouping the years using a standard process would not have the same impact. The one observation for 33 years is Stage 4 CTE. So the final bar in the graph shows 100%. This supports that theory that more years of football participation increases the risk of severe CTE.
However, I find it somewhat deceptive. Using equal intervals to group the data gives a less dramatic visualization:
Attempt3
Final prompts
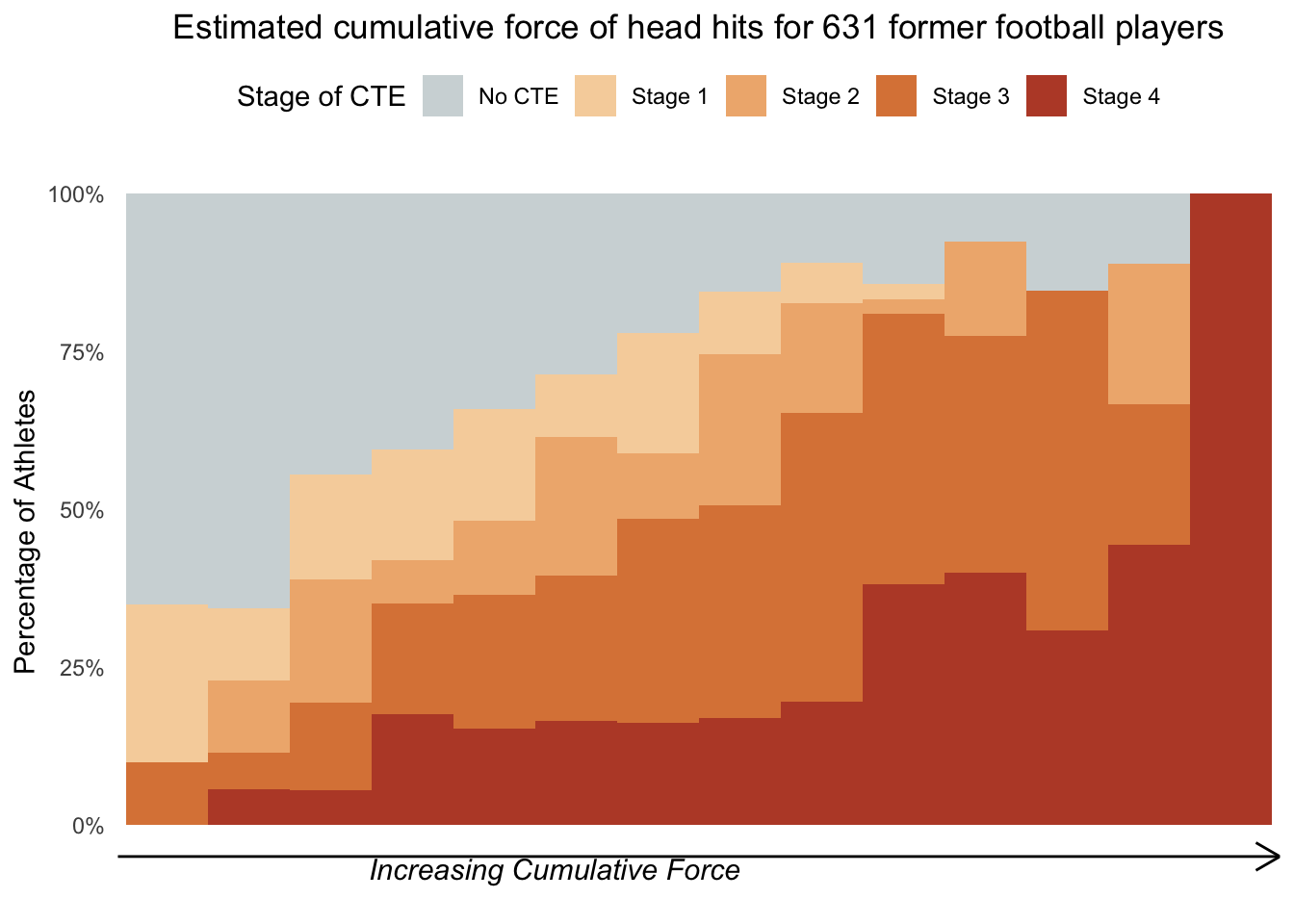
In order to match the colors, I used the color picker tool in Powerpoint. ChatGPT is not able to identify hex codes from an image. I also instructed ChatGPT to create 14 categories with the last observation as its own category. Beyond that, I tried using equal interval, jenks and natural breaks to mimic the rest of the data groupings, but I could not exactly recreate the NYT image.
Looking that the data once more, I noticed that the NYT graph does not adequately represent the data. I could recreate the last 2 categories but the 3 to last grouping omits at least 2 records.
Stage 2 CTE is missing from the NYT graph for this grouping.
Finally, I provided prompts to remove the numbers on the X axis and preplace them with “Increasing Cumulative Force” and also include an arrow point from left to right.
Final version
While my final version does not match the NYT graphic, earlier iterations matched the original graphic published in the academic journal. Below is the final code used to recreate the graph.
library(readxl)library(dplyr)library(here)library(ggplot2)library(classInt)library(scales)# Set the correct path to the Excel filefile_path <-here("presentation-exercise", "EX6_mod.xlsx")# Read the data from the Excel filedf <-read_excel(file_path)# Ensure 'football_years' is numericdf$football_years <-as.numeric(df$football_years)# Define the breaks manually, ensuring the last break is 33 to create its own category# Adjust the breaks as necessary to fit the categorization you observedmax_years <-max(df$football_years, na.rm =TRUE)n_groups <-13# One less than before since 33 will be its own groupjenks_breaks <-classIntervals(df$football_years[df$football_years < max_years], n = n_groups, style ="jenks")$brks# Ensure 33 is its own categoryfinal_breaks <-c(jenks_breaks, max_years-1, max_years)# Group 'football_years' using these breaksdf$year_group <-cut(df$football_years, breaks = final_breaks, include.lowest =TRUE, labels =FALSE)# Convert 'CTEStage' to a factor with correct levelsdf$CTEStage <-factor(df$CTEStage, levels =c(0, 1, 2, 3, 4))# Proceed with summarizing and plotting as beforedf_summary <- df %>%group_by(year_group, CTEStage) %>%summarise(count =n(), .groups ="drop") %>%left_join(df %>%group_by(year_group) %>%summarise(total =n(), .groups ="drop"), by ="year_group") %>%mutate(percentage = count / total)# Calculate the count for each year group and CTE stagedf_summary <- df %>%group_by(year_group, CTEStage) %>%summarise(count =n(), .groups ="drop")# Calculate the percentage for each year group and CTE stagetotal_counts <- df_summary %>%group_by(year_group) %>%summarise(total =sum(count), .groups ="drop")df_summary <- df_summary %>%left_join(total_counts, by ="year_group") %>%mutate(percentage = count / total)# Plot the percentages as a stacked bar graph scaled to the same heightggplot_object <-ggplot(df_summary, aes(x =as.factor(year_group), y = percentage, fill =as.factor(CTEStage))) +geom_bar(stat ="identity", position ="fill", width =1) +scale_fill_manual(values =c("0"="#D0D8DA","1"="#F6D3AA","2"="#EFB47D","3"="#DC8445","4"="#BA4B32"),labels =c("No CTE", "Stage 1", "Stage 2", "Stage 3", "Stage 4")) +scale_y_continuous(labels = percent) +labs(x =NULL, # Remove default x-axis titley ="Percentage of Athletes", fill ="Stage of CTE",title ="Estimated cumulative force of head hits for 631 former football players") +theme_minimal() +theme(legend.position ="top", # Move legend to the topaxis.ticks.x =element_blank(), # Remove x-axis ticksaxis.text.x =element_blank(), # Remove x-axis textplot.title =element_text(hjust =0.5), # Center the plot titlepanel.grid.major =element_blank(), # Remove major grid linespanel.grid.minor =element_blank(), # Remove minor grid linespanel.background =element_blank()) +# Remove panel backgroundannotate("text", x =Inf, y =-0.07, label ="Increasing Cumulative Force", hjust =2.45, vjust = .5, size =4, fontface ="italic") +annotate("segment", x =-Inf, xend =Inf, y =-0.05, yend =-0.05, arrow =arrow(type ="open", ends ="last", length =unit(0.15, "inches"))) # Adjusted length#annotate("segment", x = -Inf, xend = Inf y = -0.05, yend = -0.05, arrow = arrow(type = "open", ends = "last", length = unit(0.5, "inches")))# Plot the graphprint(ggplot_object)
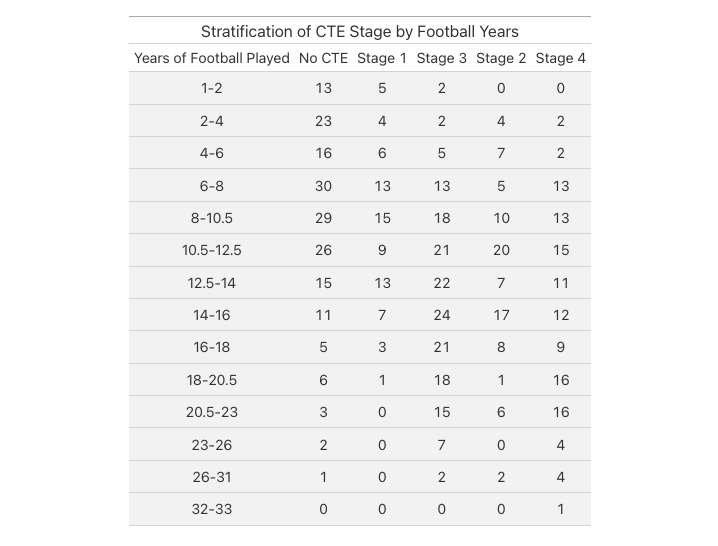
Publication style table
After creating the graph, creating the table was much easier. I used some of the code from creating the graph to ensure the year groupings were the same. Here is the prompt I used:
I want to make a publication-ready table using a style required for the journal Nature that stratifies CTEStage by football_years from the .xlsx sheet using the same breaks defined in the chart with this code: max_years \<- max(df$football_years, na.rm = TRUE) n_groups <- 13 # One less than before since 33 will be its own group jenks_breaks <- classIntervals(df$football_years\[df$football_years < max_years], n = n_groups, style = "jenks")$brks
Ensure 33 is its own category final_breaks \<- c(jenks_breaks, max_years-1, max_years) the strata should be labeled with their range of football_years. finally, can you make sure that the table matches the style of the stacked graph?
Code for table
library(classInt)
library(gt)
library(readxl)
library(dplyr)
library(webshot2)
library(here)
library(tidyr)
# Read the data from the Excel file
file_path <- here("presentation-exercise", "EX6_mod.xlsx")
df <- read_excel(file_path)
# Ensure 'football_years' is numeric
df$football_years <- as.numeric(df$football_years)
# Define the breaks as per your code snippet
max_years <- max(df$football_years, na.rm = TRUE)
n_groups <- 13 # Adjust based on the specific needs
jenks_breaks <- classIntervals(df$football_years[df$football_years < max_years], n = n_groups, style = "jenks")$brks
# Ensure 33 is its own category
final_breaks <- c(jenks_breaks, max_years-1, max_years)
# Stratify football_years using the breaks
df$year_strata <- cut(df$football_years, breaks = final_breaks, include.lowest = TRUE,
labels = paste(head(final_breaks, -1), tail(final_breaks, -1), sep = "-"))
# Convert 'CTEStage' to a factor with correct levels
df$CTEStage <- factor(df$CTEStage, levels = c(0, 1, 2, 3, 4))
# Summarize the data
df_summary <- df %>%
group_by(year_strata, CTEStage) %>%
summarise(count = n(), .groups = "drop") %>%
pivot_wider(names_from = CTEStage, values_from = count, values_fill = list(count = 0))
gt_table <- df_summary %>%
gt() %>%
tab_header(
title = "Stratification of CTE Stage by Football Years"
) %>%
cols_label(
year_strata = "Years of Football Played",
`0` = "No CTE",
`1` = "Stage 1",
`2` = "Stage 2",
`3` = "Stage 3",
`4` = "Stage 4"
) %>%
tab_options(
heading.title.font.size = px(18),
heading.subtitle.font.size = px(10)
) %>%
tab_style(
style = list(
cell_text(align = 'center'),
cell_fill(color = "gray95")
),
locations = cells_column_labels(columns = TRUE)
)
# If you intended to add more styling or options, they would continue here
# Display the table
print(gt_table)