Analyzing text from public comments for REG 2023-02, Artificial Intelligence in Campaign Ads
Introduction:
The source of the text for this exercise come from public comments in response to Public Citizens second petition for rulemaking to the Federal Election Commission (FEC) in July, 2023. Public Citizen asked the FEC to clarify the subject of “fraudulent misrepresentation” regarding the use of AI, including deep fake technology, and open a Notice of Availability that would allow public comment.
Fifty pdfs were downloaded from the FEC site. Each pdf contained comments in response to Public Citizens petition.
These fifty documents made up the corpus for the text analysis. The process is described below.
if (!require(syuzhet)) {install.packages("syuzhet")}
here() starts at /Users/andrewruiz/andrew_ruiz-MADA-portfolio
Process:
Locate and read the PDFs
# Specify the folder containing the PDFspdf_folder <-here("data-exercise", "data", "raw-data")# Read all PDF files from the folderfile_list <-list.files(path = pdf_folder, pattern ="*.pdf", full.names =TRUE)
Process files
Now that the files are located and read, we will begin processing them for analysis
# Extract text from each PDFtext_data <-lapply(file_list, pdf_text)# Combine the text into one character vector, one element per PDFtext_data_combined <-sapply(text_data, paste, collapse =" ")# Create a corpus from the combined textdocs <-Corpus(VectorSource(text_data_combined))
Cleaning the text
To analyze the text we will need to clean in and prepare it for use.
clean_corpus_initial <-function(corpus) { original_length <-length(corpus)# convert text to lowercase corpus <-tm_map(corpus, content_transformer(tolower))# remove punctuation corpus <-tm_map(corpus, removePunctuation)# remove numbers corpus <-tm_map(corpus, removeNumbers)# remove stop words (common words like 'the', 'and', 'is) corpus <-tm_map(corpus, removeWords, stopwords("english"))# remove extra whitespaces corpus <-tm_map(corpus, stripWhitespace)# Return the cleaned corpus along with the indices of dropped documentsreturn(list(corpus = corpus, original_length = original_length))}# Apply initial cleaningresult <-clean_corpus_initial(docs)
Warning in tm_map.SimpleCorpus(corpus, content_transformer(tolower)):
transformation drops documents
Warning in tm_map.SimpleCorpus(corpus, removePunctuation): transformation drops
documents
Warning in tm_map.SimpleCorpus(corpus, removeNumbers): transformation drops
documents
Warning in tm_map.SimpleCorpus(corpus, removeWords, stopwords("english")):
transformation drops documents
Warning in tm_map.SimpleCorpus(corpus, stripWhitespace): transformation drops
documents
# There was a warning that documents had been dropped. This code will check to see which ones and how many.corpus_cleaned <- result$corpusoriginal_length <- result$original_lengthcat("Original number of documents:", original_length, "\n")
Original number of documents: 50
cat("Number of documents after cleaning:", length(corpus_cleaned), "\n")
Number of documents after cleaning: 50
cat("Number of documents dropped:", original_length -length(corpus_cleaned), "\n")
Number of documents dropped: 0
# Identify the indices of dropped documentsdropped_indices <-setdiff(1:original_length, 1:length(corpus_cleaned))cat("Indices of dropped documents:", paste(dropped_indices, collapse =", "), "\n")
Indices of dropped documents:
# The output indicates that zero documents were dropped
Now that the text is clean we can proceed to the next step.
# Create a Document-Term Matrix (DTM) from the cleaned text documents (docs_cleaned_initial).# Remove rows (documents) from the DTM where the sum of term frequencies is zero,# effectively filtering out empty documents.dtm_initial <-DocumentTermMatrix(corpus_cleaned)dtm_initial <- dtm_initial[rowSums(as.matrix(dtm_initial)) >0, ]
We will now create a Latent Dirichlet Allocation (LDA) model. An LDA is statistical model used in natural language processing and machine learning.
# Set the number of topics to 8# this can be modified depending on the need and resultsk_initial <-8# Create an LDA model using the Document-Term Matrix (dtm_initial) with the specified number of topics.# Control parameters may include the random seed for reproducibility (seed = 4321).lda_model_initial <-LDA(dtm_initial, k = k_initial, control =list(seed =4321))# Retrieve the terms associated with each topic, specifying a maximum of 8 terms per topic.topics_initial <-terms(lda_model_initial, 8)# Print the initial topics along with potential terms that describe each topic.print("Initial topics with potential names included:")
[1] "Initial topics with potential names included:"
We now have 8 topics with the most common words associated with each topic. Notice that topic 2 is a list of first names. This is not especially helpful in this case. However, let’s proceed with these topics and see if we can fix them later. Next we will see the theme associated with each document.
# Extract the topic for each document for the initial modeltopic_probabilities_initial <-posterior(lda_model_initial)$topicsdoc_topics_initial <-apply(topic_probabilities_initial, 1, which.max)# Create a data frame for the document-topic associations for the initial modeldoc_topics_df_initial <-data.frame(Document =names(doc_topics_initial), MostLikelyTopic = doc_topics_initial)# View the first few rows of the document-topic association for the initial modelhead(doc_topics_df_initial)
Let’s include those names in the stopword list to see if the results are better.
# Extend the stopwords list with common names for refined cleaningcustom_stopwords <-c(stopwords("en"), "john", "patricia", "donna", "susan", "linda", "margaret", "thomas", "david")# Refined cleaning function that includes removal of first namesclean_corpus_refined <-function(corpus) { corpus <-tm_map(corpus, content_transformer(tolower)) corpus <-tm_map(corpus, removePunctuation) corpus <-tm_map(corpus, removeNumbers) corpus <-tm_map(corpus, removeWords, custom_stopwords) corpus <-tm_map(corpus, stripWhitespace)return(corpus)}# Apply refined cleaningdocs_cleaned_refined <-clean_corpus_refined(docs)
Warning in tm_map.SimpleCorpus(corpus, content_transformer(tolower)):
transformation drops documents
Warning in tm_map.SimpleCorpus(corpus, removePunctuation): transformation drops
documents
Warning in tm_map.SimpleCorpus(corpus, removeNumbers): transformation drops
documents
Warning in tm_map.SimpleCorpus(corpus, removeWords, custom_stopwords):
transformation drops documents
Warning in tm_map.SimpleCorpus(corpus, stripWhitespace): transformation drops
documents
Now let’s rerun the code with the refined text.
# DTM for refined analysisdtm_refined <-DocumentTermMatrix(docs_cleaned_refined)dtm_refined <- dtm_refined[rowSums(as.matrix(dtm_refined)) >0, ]# Refined topic modelingk_refined <-8lda_model_refined <-LDA(dtm_refined, k = k_refined, control =list(seed =4321))topics_refined <-terms(lda_model_refined, 8)print("Refined topics without first names:")
So it turns out that adding the names as stop words was not that helpful. It jsut returned another topic filled with names. For now, we will move on.
# Extract the topic for each document for the refined modeltopic_probabilities_refined <-posterior(lda_model_refined)$topicsdoc_topics_refined <-apply(topic_probabilities_refined, 1, which.max)# Create a data frame for the document-topic associations for the refined modeldoc_topics_df_refined <-data.frame(Document =names(doc_topics_refined), MostLikelyTopic = doc_topics_refined)# View the first few rows of the document-topic association for the refined modelhead(doc_topics_df_refined)
It turns out that topic two is not associated with documents 1-6 now that names were added to the stopword list. More investigation would be needed to uncover the meaning of this. ## Sentiment analysis now let’s take a look at the sentiment for each document. For this we will use the Bing method
# Perform sentiment analysis on the combined text datasentiment_scores <-get_sentiment(text_data_combined, method ="bing")# View the sentiment scoreshead(sentiment_scores)
[1] -6 -24 -6 30 11 -8
# Create a vector of PDF document namespdf_document_names <-basename(file_list)# Create a data frame with document names and sentiment scoressentiment_df <-data.frame(DocumentName = pdf_document_names, SentimentScore = sentiment_scores)# Print the first few rows of the data frame to see the mappinghead(sentiment_df)
For the text used in this analysis, the sentiment may be a little misleading. These comments were written in support of a second petition for the FEC to allow public comments of rulemaking. Most public comments in these forums begin by thanking the regulatory agency for allowing comments. Those sections tend to be very positive. However, the comments often continue by describing potential problem. Those tend to use negative language. The Bing method results are centered around 0. A zero score indicates completely neutral setiment. The larger negative scores indicate negative sentiment. Large positive scores indicate positive sentiment.
Let’s take a look at a different way to identify sentiment. For this we will use the NRC method which classifies sentiment into categories that may make better sense of the data.
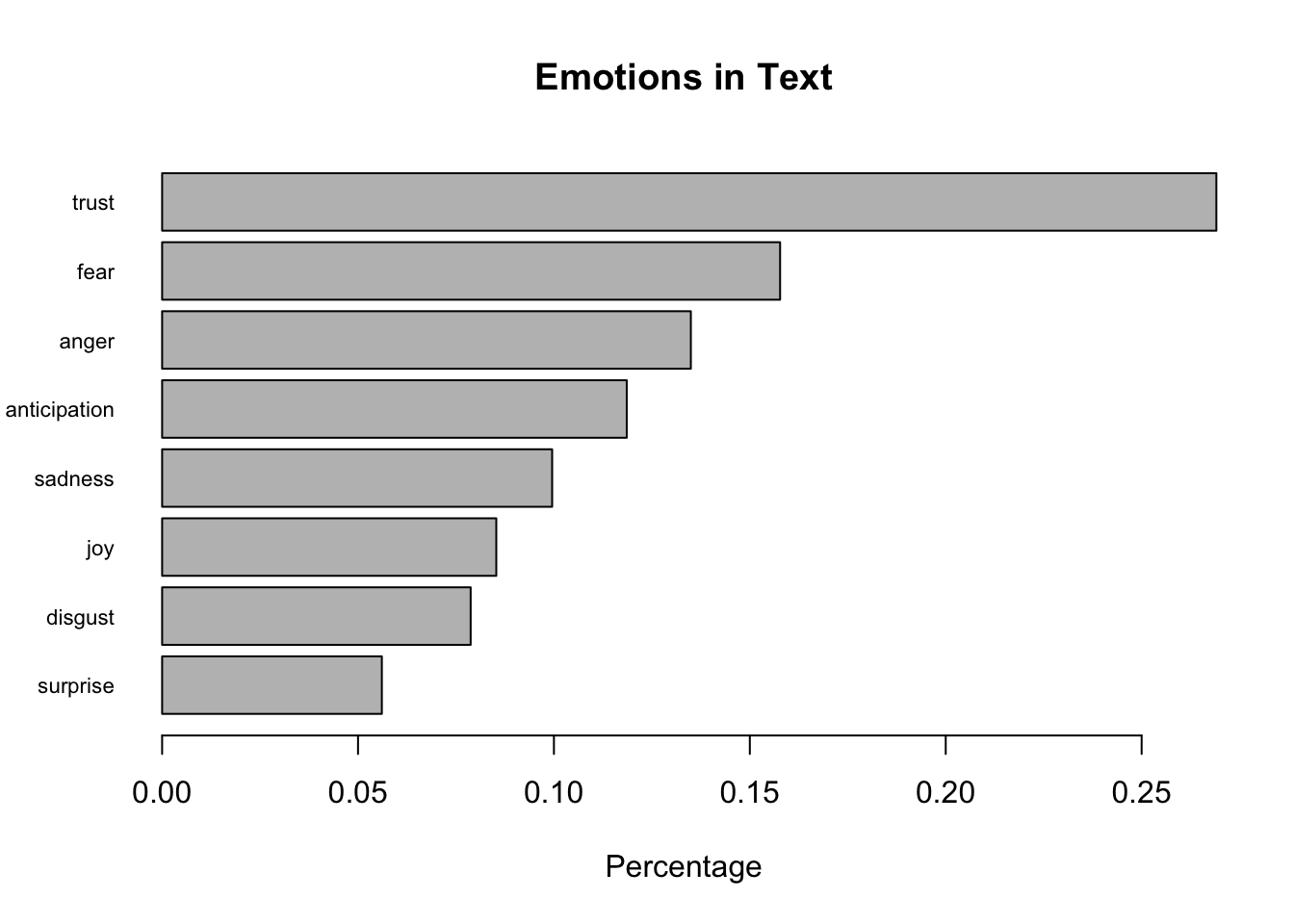
These results display word counts for the number of words in each document that fall into NRC’s sentiment categories. The bar graph represents the percent to words that fall into each category. The barchart represents all the text across all 50 documents.
# define the datanrc_data <-get_nrc_sentiment(text_data_combined)# Access the data frame columns for emotions and sentiments#anger_items <- which(nrc_data$anger > 0)#joy_items <- which(nrc_data$joy > 0)# Print sentences associated with specific emotions#print(text_data_combined[anger_items])#print(text_data_combined[joy_items])# View the entire sentiment data frameprint(nrc_data)
document_sentiment <-data.frame(DocumentName = pdf_document_names, Negative = nrc_data$negative, Positive = nrc_data$positive)# Print the data frame with document names and sentiment scoresprint(document_sentiment)
# Create a bar graph of emotionsbarplot(sort(colSums(prop.table(nrc_data[, 1:8]))), horiz =TRUE, cex.names =0.7, las =1, main ="Emotions in Text", xlab ="Percentage")